
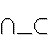






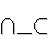


URLの履歴
使える文字、使えない文字
unsafe:
" ", "<", ">", """, "#", "%" , "{", "}", "|", "\", "^", "~", "[", "]", "`"
reserved:
";", "/", "?", ":", "@", "=" and "&"
BNF
; HTTP
httpurl = "http://" hostport [ "/" hpath [ "?" search ]]
hpath = hsegment *[ "/" hsegment ]
hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ]
search = *[ uchar | ";" | ":" | "@" | "&" | "=" ]
; Miscellaneous definitions
lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" |
"i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" |
"q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" |
"y" | "z"
hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "I" |
"J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" |
"S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z"
alpha = lowalpha | hialpha
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" |
"8" | "9"
safe = "$" | "-" | "_" | "." | "+"
extra = "!" | "*" | "'" | "(" | ")" | ","
national = "{" | "}" | "|" | "\" | "^" | "~" | "[" | "]" | "`"
punctuation = "<" | ">" | "#" | "%" | <">
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "="
hex = digit | "A" | "B" | "C" | "D" | "E" | "F" |
"a" | "b" | "c" | "d" | "e" | "f"
escape = "%" hex hex
unreserved = alpha | digit | safe | extra
uchar = unreserved | escape
xchar = unreserved | reserved | escape
digits = 1*digit
http://tools.ietf.org/html/rfc1738
punctuationは文章中に区切りとして使われそうなやつ。故にunsafe
nationalって何なんだろ
